2025.02.17 월요일
크롤링이 데이터를 찾는 작업이라면, 스크래핑은 데이터를 추출하는 작업.
크롤링은 스크래핑의 첫 번째 단계가 될 수 있다.
ex) 웹사이트 전체를 크롤링해 필요한 페이지를 발견한 후, 해당 페이지에서 데이터를 스크래핑
크롤링과 스크래핑은 '원하는 데이터를 모을수 있다'는 점이 비슷.
BUT, 웹 크롤링은 웹 페이지 링크를 타고 계속해서 탐색을 이어나가지만,
웹 스크래핑은 데이터 추출을 원하는 대상이 명확하여 특정 웹사이트만을 추적한다는 차이점 !
웹 크롤링
: 페이지를 모아 분류하고 검색 결과에 내가 찾는 키워드와 연관된 링크들만 모아 볼 수 있도록 작동.
웹 스크래핑
: 상품의 가격, 주식정보, 뉴스 등 원하는 데이터가 명확하며, 흩어져 있는 해당 데이터를 자동으로 추출하여 전달.
robots.txt
웹 사이트 소유자가 크롤러에게 제공하는 지침서로, 크롤러가 접근할 수 있는 영역과 접근할 수 없는 영역을 명확하게 정의해놓은 파일 !!
robots.txt 파일의 역할
크롤링 제한 / 서버 부하 감소 / 사이트 맵 제공
User-agent : 크롤러를 식별하는 부분. 특정 크롤러 또는 모든 크롤러에 대한 지침을 제공
Disallow : 크롤링을 금지할 디렉토리, 페이지를 지정
Allow : (Disallow와 함께 사용될 때) 크롤링을 허용할 디렉토리, 페이지를 지정
Sitemap : 사이트 맵 파일의 위치를 제공
User-agent: Mediapartners-Google => google 크롤러에게 적용
Disallow: /screener/insider/ => 접근 금지
Allow: /caas/ => 접근 가능
request : 서버에 데이터 요청
response : 서버가 요청 데이터를 보내줌
파이썬 + 뷰티풀수프 : 데이터 속에서 원하는 데이터 찾기
HTML 구성
<html>
<head></head>
<body> 사용자 화면 내용
<p></p>
<h1></h1>
<img src = "">
<input type = ""/>
<div id = "" class = "" ></div><span></span>
class ="" : 주로 CSS를 지정
class = "f_gb b_gb bg_color"
id = "" : 주로 Javascript 에서 태그를 다룰 때..
</body>
</html>
- 웹 크롤링 : 페이지 변화
- 웹 스크래핑 : 데이터 마이닝 작업 => URL => 웹 페이지 구조 => 뷰티풀숩
- URL 요청 라이브러리 => request
+ 실습 프로젝트
1. 크롤링할 url 을 BeautifulSoup으로 html 만들기
stock_url = 'https://finance.yahoo.com/quote/005930.KS/history/'
# 웹 페이지 요청 : requests.get()
res = requests.get(stock_url)
#=> <Response [429]>
# 응답에서 HTML 문서만 가져오기 : requests.text
html = res.text
#=> 'Edge: Too Many Requests'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7'
}
# User-Agent 는 모질라 / 애플웹킷 / 크롬 / 사파리를 통해 가능
# accept 는 허용하는 것
# stock_url를 그냥 요청하는 것이 아니라, 헤더를 담아 요청
res = requests.get(stock_url, headers = headers)
html = res.text
soup = BeautifulSoup(html, 'html.parser')
2. 해당 페이지에서 내가 찾고자 하는 요소 파악
* 날짜 / 종가 찾기
soup.find_all('td', class_ = first_class)
'''
<td class="yf-1jecxey">59,100.00</td>,
<td class="yf-1jecxey">58,699.75</td>,
<td class="yf-1jecxey">19,838,511</td>,
<td class="yf-1jecxey">Oct 29, 2024</td>,
<td class="yf-1jecxey">58,000.00</td>,
<td class="yf-1jecxey">59,600.00</td>...
'''
+ find => 한 개 찾기
+ find_all => 요청에 맞는 모든 요소 찾기
3. 내가 원하는 형식에 맞게 바꾸기
# 2024년 11월 17일 : Feb 17, 2024 - Feb 17, 2025
# 52,000원 : 52,000.00
# YYYY년 MM월 DD일인 형식으로 날짜(Date) 처리 :
# strftime('%Y년 %m월 %d일')
datef = pd.to_datetime(soup.find_all('td', class_ = first_class)[0].text).strftime('%Y년 %m월 %d일')
#=> '2025년 02월 17일'
# .00을 '원'으로 대체하여 종가(Close) 처리 :
# replace('.00','원')
closeP = soup.find_all('td', class_ = first_class)[4].text.replace('.00','원')
#=> '55,900원'
+ 전체 for 문으로 돌려서 적용
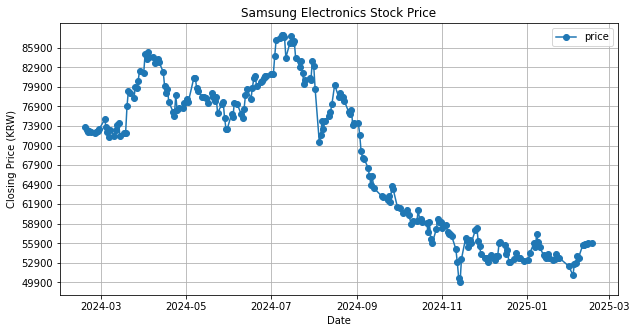
4. 시계열 시각화 진행
'[LG U+ 5기] > Project' 카테고리의 다른 글
| [2월][4주차][SQL] 데이터베이스 구축 : 테이블 설계부터 ERD까지 (0) | 2025.02.27 |
|---|---|
| [2월][3주차] 병원 노쇼 분석 프로젝트🤕 (0) | 2025.02.22 |
| [2월][3주차] 주식 시세 예측 분석📈 (0) | 2025.02.22 |
| [2월][3주차] 🏥의료데이터 분석 프로젝트 (0) | 2025.02.17 |
| [2월][2주차] 넷플릭스 분석 프로젝트 (0) | 2025.02.14 |